Project
PolicyTrace
A Document AI workflow for UK motor insurance PDFs, with structured extraction, provenance, conflict resolution, and human review.
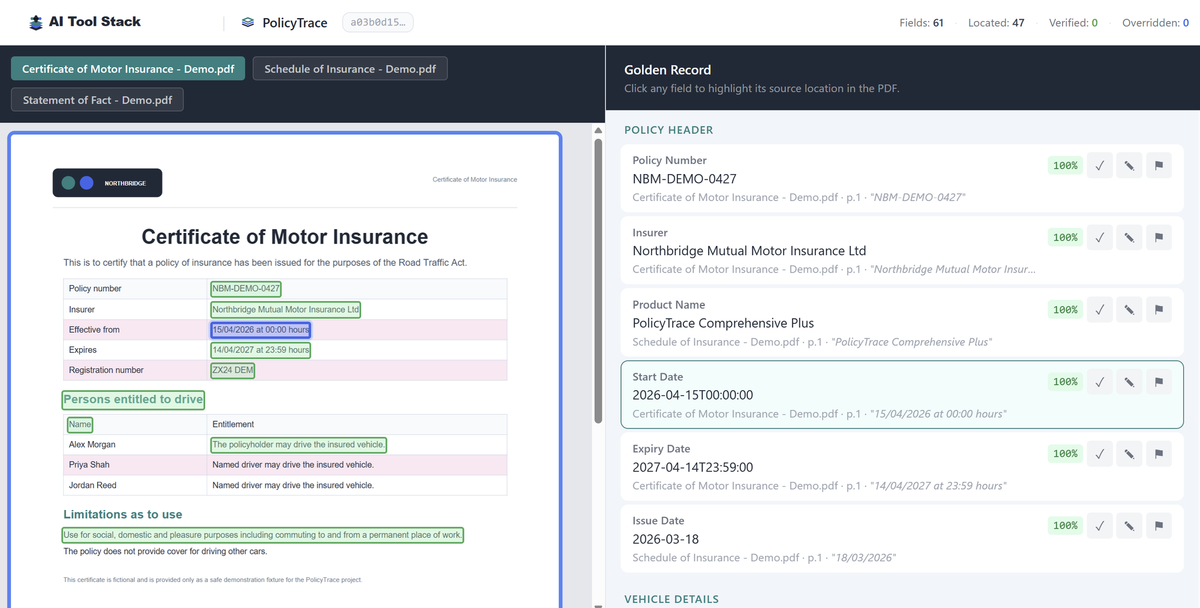
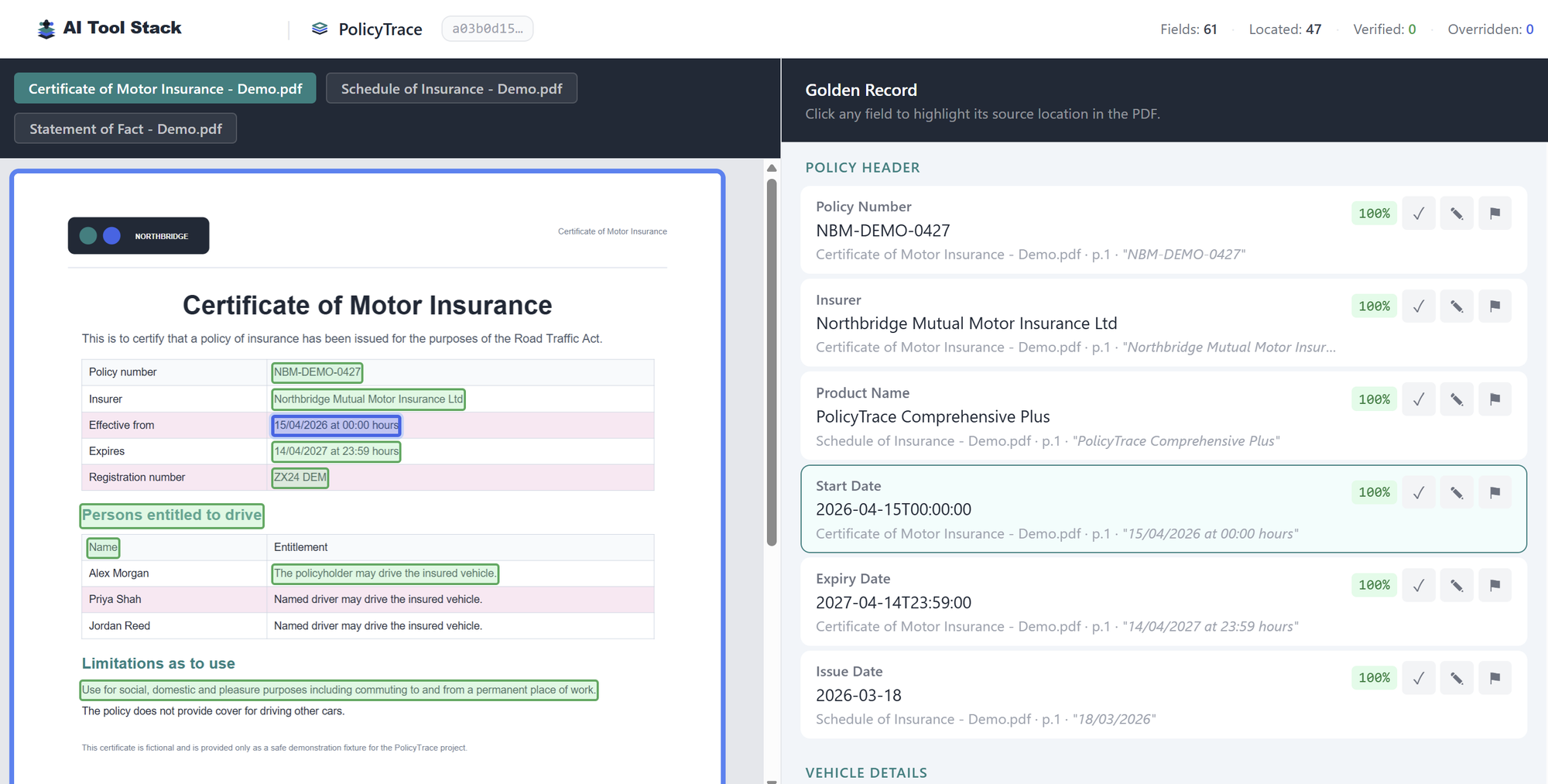
Split-screen review: source PDF evidence on the left, typed Golden Record fields and review controls on the right.
PolicyTrace turns a messy insurance document pack into a typed Golden Record, then keeps the evidence trail close enough for a reviewer to inspect, verify, flag, or override individual fields.
The Schedule, Certificate, Statement of Fact, and Policy Booklet are classified before extraction so the system can treat them differently.
The arbiter decides which document wins for each field and surfaces conflicts instead of silently hiding disagreement.
Verbatim field citations and Docling geometry are used to connect extracted values back to PDF locations.
System Flow
From policy pack to Golden Record.
The model is one step in the workflow. Parsing, masking, validation, arbitration, provenance, and review are separate control points.
PDF Pack
Schedule, Certificate, Statement of Fact, and Policy Booklet enter as a document set.
Docling Parse
Text and layout are converted while preserving enough geometry for later field matching.
PII Mask
Presidio masks sensitive entities before model calls while dates remain available for extraction.
Classify
A fast classifier routes each document to the right extraction prompt and fallback path.
Extract
Groq, Instructor, and Pydantic produce typed partial records and verbatim field citations.
Arbitrate
The PolicyArbiter applies hierarchy-of-truth rules and records cross-document conflicts.
Provenance
Canonical values and source quotes are matched back to PDF text locations.
Review UI
FastAPI and React expose the Golden Record, source PDFs, highlights, and review state.
Engineering Decisions
What makes this more than PDF-to-JSON.
These are the reusable patterns the project demonstrates. They matter more than any single prompt.
Hierarchy of truth
The Schedule wins for vehicle, premium, excess, and driver-risk fields. The Certificate wins for legal driving permissions and class of use.
Typed Golden Record
Pydantic keeps downstream JSON predictable while optional fields allow partial per-document extraction before the final merge.
Evidence matching
The LLM supplies verbatim citations. A separate matcher connects those phrases to Docling PDF geometry, reducing geometry hallucination risk.
Selective masking
PII is masked before extraction, but date masking stays off because policy dates are core extraction data.
Versioned prompts
Extraction prompts are configured and versioned outside code, so changes can be audited and improved without rewriting the pipeline.
Review state
The API stores verify, reject, and override actions so human review becomes part of the workflow, not a screenshot afterthought.
Project Series
Core chapters first. Implementation notes second.
The first column is the PolicyTrace system design document: architecture, truth, evidence, conflict, and review. The second column is supporting implementation work: deployment, hardening, evaluation, and prompt design.
-
01
Layered architecture
What components exist, where the boundaries sit, and why this is not just PDF to JSON.
-
02
The Golden Record problem
How PolicyTrace decides canonical truth when insurance documents overlap.
-
03
Evidence and provenance
Why JSON alone is insufficient, and how values connect back to source text and PDF location.
-
04
Conflict and arbitration
How disagreement becomes visible state instead of a silent overwrite.
-
05
Human review workflow
How reviewers inspect evidence, verify fields, flag uncertainty, and override values.
-
A
Deployment
GitHub, Docker, FastAPI, React, and Hugging Face Spaces.
-
B
Production hardening
Auth, storage, queues, audit logs, monitoring, retention, and ownership.
-
C
Evaluation
Golden examples, conflict fixtures, evidence quality, review outcomes, and gates.
-
D
Prompt design
Prompts as a bounded layer that feeds typed outputs, citations, provenance, and review.
Evidence Trail
Canonical value, source quote, PDF location.
PolicyTrace separates the value used by the system from the phrase used to find the source. That matters when a date, amount, or name is normalized.
Certificate of Motor Insurance
System Shape
A reference architecture for document-heavy AI workflows.
The same shape can later be reused for claims, compliance, onboarding, lending, audits, and other multi-document workflows.
Input control
PDF upload, file type checks, safe filenames, per-session storage, and page caps for long documents.
Model control
Classification and extraction are separated, with specialist prompts and structured validation retries.
Domain control
The arbiter applies insurance-specific source authority rules instead of trusting whichever model answer arrives last.
Review control
Reviewers see extracted fields, confidence, source snippets, PDF highlights, and override actions in one place.
Honest Limits
Useful demo, not a finished insurance production system.
The project is intentionally honest about the gap between a public demo and a controlled production workflow.
Explore The Project
Try the workflow, then inspect how it is built.
The demo shows the review experience. The repository shows the architecture, source decisions, and implementation details behind it.